Optimising a read mostly write sometimes application
About 6 years ago I created a web based application using J2EE, a DAO layer using JDBC to a PostgreSQL database. The J2EE application container ran on its own server, and the PostgreSQL on a dedicated server as well. The two servers were connected with fast gigabit ethernet. The DB is located on a SAN attached to the database server using Fibre Channel.
The main database size has since grown, and is now 110GB. The largest table has about 180 million rows, and there are about 136 tables. When I wrote it originally, multicored CPU's did not exist. Servers with multiple CPU's did, but the system was never deployed on such a configuration.
There is a process that runs once a month that performs a lot of reads on the database, perform some calculations and then writes the data to several tables. This process recently took 491 minutes to complete.
Since the new servers have dual core Xeon processors with hyperthreading, I decided to perform some optimisations. There were several optimisations that helped a lot, but one stood out. That was to split the processing engine to spread the load across multiple threads. Obviously this was not done originally as it would not have had any benefit on a single core CPU, and it is complicated.
Since I could not test this on production, I tested it instead on my own development environment. The app server had a Core i7 930 CPU with 4 cores (8 with hyperthreading), and the DB server had a Core i7 950 with 4 cores (8 with hyperthreading). Also, I did not have the funds to purchase a R2mil SAN, so I had to make do with a Western Digital Caviar Black 1TB SATA 7200rpm drive.
To make this test more interesting, I also purchased a fast OCZ Vertex 3 240GB SSD. I furthermore looked at the impact when the application server and DB server are co-located. Do take note that on the fewer Xeon cores on production, co-location is not going to provide as much benefit as in my case where I had 4/8 cores. Also take note that extra load is usually on production besides this monthly processing, which scales better with the split configuration.
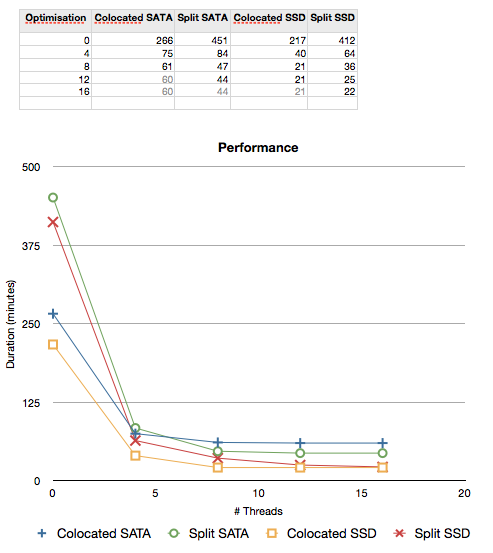
The results speak for themselves. Co-location is faster than a split configuration when nothing is optimised (but do remember, other tasks run as well so one cannot merely co-locate and think there will be a global performance increase.). Co-location is slower than split when the database storage device is not incredibly fast. Only a super fast SSD matches co-location with split, and even then the co-located setup is better due to the other load placed on the system. More threads improve performance more when using an SSD than a slower SATA hard drive - hence scalability is better with a faster disk. The split configuration scales better than the co-located configuration, and I am sure this effect will be more pronounced if I had fewer cores. The huge amount of cores allows for better scaling on a co-located configuration.
The best performance is with as many cores as possible, with the application and DB servers co-located. But once again, this is up to a point. To go beyond that will require a split configuration.
The lesson to learn from this is use co-location when the load is small - it is faster. As your load grows, prefer colocation but only if you have multiple cores. Keep on adding more cores until the server is maxed out. If the load grows even more, then you will have to go to a split configuration that will scale even further.